Sat, 2026-05-30 20:28
还记得2024年秋季,在我们组织的第二期晋北团中,曾有团友发出过这样一则灵魂拷问:“在旅途中,我们是否有必要拍照?因为网上随便一搜就有大量现成的照片,又多又好,那在现场我们不如专注于看和听,想回顾时直接翻网图就好。”几乎是在提出问题的同时,我就听到有其他朋友在小声嘀咕:“这叫啥问题啊,想拍就拍呗!”
细品之后,我感觉这真是个有趣的问题。在我看来,拍照与否,不在于攀比或省事儿。无论好坏,每一张照片记录的都是当下的自己,它所记录的不仅是影像与奇遇,而更多是我们在按下拍摄键那一刻的视野、审美、好奇心以及观察世界的角度,甚至还包含了心情,等等等等。试想若干年后,当我们再翻看起这些照片或者故地重游时,或许还能与曾经的自己再来一场跨越时空的邂逅吧~
Blog大概也如此,它在时光的维度上,记录了每一时刻的自己,它不是影像而是思想,它没有色彩却又五彩斑斓。人无时无刻不在改变,我想用手机做一个抓拍者,记录众生;亦想用blog抓拍自己,用文字记录下那个处于不同阶段的、限定版的“我”。
所以为什么一定要自建一个blog?我想,这不单单是想要一个具有排他性的自留地,而更多是想要一种完全的掌控力。我想要一个轻简的页面,这不限于从字体到配色、从布局到排版都要做到“简”与“洁”,那些花里胡哨、乱七八糟的功能也要通通抛弃,我希望能让自己专注于写,让看客们专注于读。因此这个blog只需有两级页面,首页和文章页,不需要传统blog的分类标签和对应的blog列表页,也没有留言版或评论区,更不需要分发或点赞,这些都可能会影响我本就有限的专注。当然,网站简约不等于简单,譬如网页上的4种基础色调(黑白蓝灰,不算页首那一点红)中的黑色(用于白色背景下正文的文字),并非css颜色代码里的#000(全黑),而是用的#333。不同于纸质印刷品,“纯黑文字+ 纯白底色”在电子设备上渲染时会对比度过高(约 21:1),长时间阅读易眼干酸胀、视觉抖动。而#333(RGB参数:51,51,51,红绿蓝数值完全相等,无偏色)对比度约 12:1,亮度约 20%,介于纯黑 #000 和中灰 #666 之间,观感清晰、缓解刺眼,阅读更舒适。同时鉴于我的blog里有大量关于欧洲古钱币的内容,为了能用深浅两种背景色展示png格式下的钱币细节,我还需要给网站配置一个读者能够随意切换白天/夜晚模式的功能。这些难以详尽的细枝末节,都是需要自定义来实现的,这便是我想要寻获的“完全的掌控力”。
在达成这个目标的道路上,也充满了各种挑战与快乐。还记得2012年那个百无聊赖的夏天,在看完伦敦奥运后,实在空虚寂寞的我决定零起步做个网站,在百度了几天后,终于靠自学搞明白了域名、服务器、域名解析、Linux+Nginx+Mysql+php环境部署、cms构站工具之间的关系,用信用卡买了Linode的vps,用支付宝从一个子公司位于加拿大的德国域名商手里注册了一个由瑞士托管的列支敦士登的.li域名,也就是现在这个xiaoguang.li,之后就投入到了关于drupal和wordpress这两款cms的比较与学习之中。
伊始,本着“差生文具多”的原则,我决定迎难而上死磕drupal,一张曾在国外程序员圈里广为流传的“cms学习难度曲线图”生动地反映了我是如何没苦硬吃的。不过还好,即便其间三天打渔两天晒网,但到2015年末我其实已经单枪匹使用views模组对advanced_forum模组进行了深度改造并完成了css的重写,基本上构建了一个可以直接上线的欧洲古钱币论坛,而且增加了很多有趣的呈现,用很多漂亮稀见的古钱币制作了论坛的各种icon和favicon。只是略有遗憾的是,随着drupal7换代到drupal8+论坛模式的衰落+微信生态的成熟以及我入职三联生活周刊,这个事儿就放下了。今天回忆起来,不遗憾,而且还挺惊叹于自己当年的干劲儿,还记得我光给论坛帖子分组做的分类树就高达上千条,当时为了确保各个分类所属关系的准确性,光翻阅各种历史书就长达近半年,而这可能不到我总工作量的百分之十,不得不感慨年轻真好。
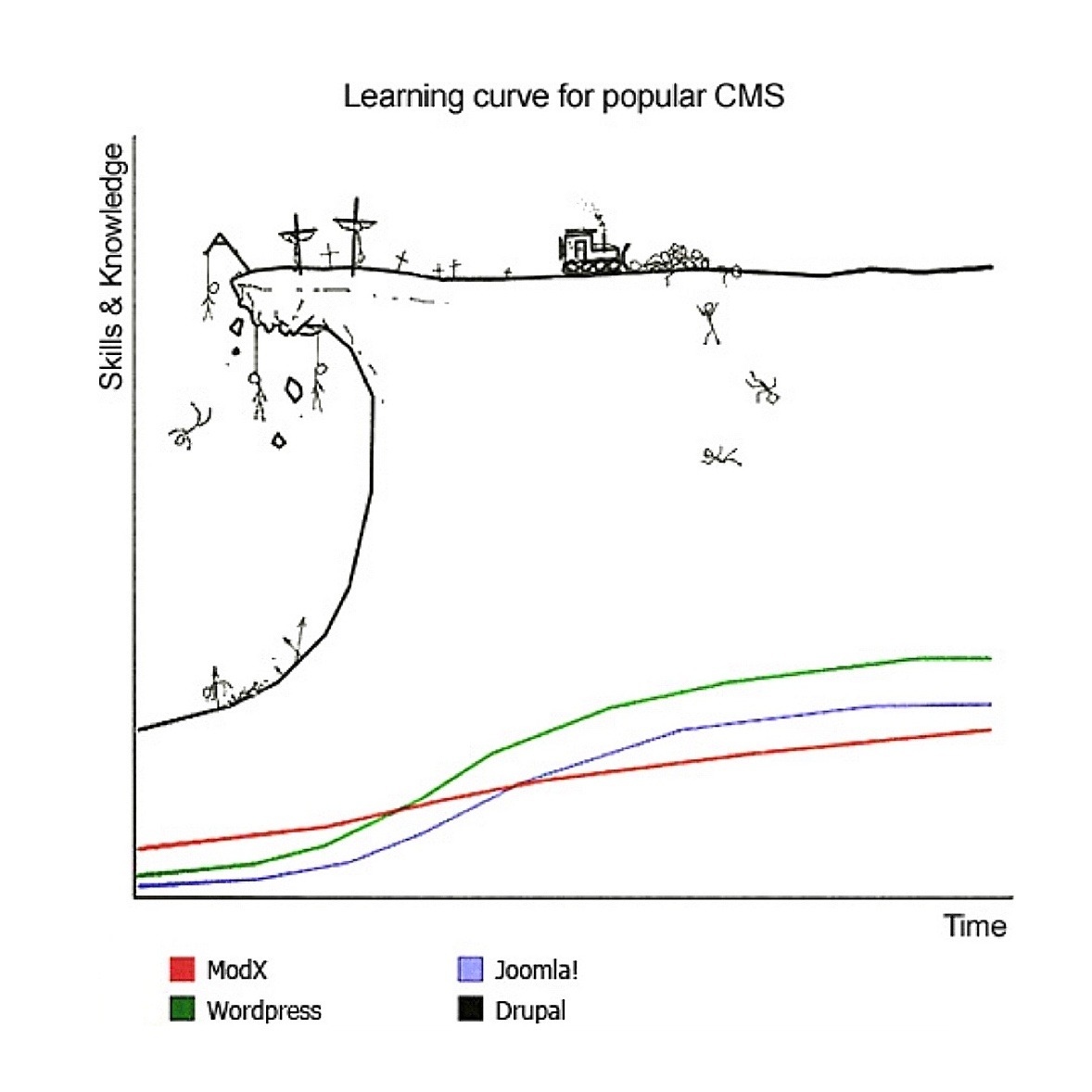
Drupal的学习难度不全在于其本身,国内资料少也是个大问题,不过好在当年有个名为“猪跑啦”(已废)的平台,可以学习到很多硬核的知识,尤其是关于views模块的。我至今依稀还记得站长“分头诗人”关于“HoneyPot(蜜罐)”这个模块的功能介绍,很是有趣。
在介绍蜜罐之前,首先要普及一下“验证码”是干什么用的?其实很多人都会有类似的疑问——为什么我经常在网页上注册或者登录时还要输入一个验证码,诸如:数字识别/汉字识别/算术题/辨认图片之类。其实这些验证码需要确认你是“真人”,而它防的是“网络机器人”。再通俗些说,这些“网络机器人”是“所有可以自动运行的、模拟人类操作的网络程序或脚本的总称”,它们可以自动注册账号并登录,然后在被攻破的网站里给其他用户私信或者公开散布各种包括但不限于黄赌毒的垃圾广告。而验证码,就是这样一道拦截网络机器人的门禁,只是道高一尺,魔高一丈,随着技术的提升,很多机器人可以通过分析网页上的html自动识别并填写出验证码,从而突破传统的验证码系统。于是HoneyPot便适时地登场了。
用一句不准确但很好理解的话来描述:一张常见而普通的网页主要是由两部分组成的——html和css,前者决定了一张网页上都有哪些内容(诸如网站名称、文章标题、文章内容、登录框、验证码等等等等),后者决定了这些内容是如何被呈现出来的(大小、颜色、透明度、旋转、剪切、展示/隐藏,等等等等)。html和css彼此关联、映射,但又分别保存在不同的文件里。而HoneyPot便利用了这一特性,对网络机器人发起了一场“诱捕”行动。HoneyPot可以在一个网页的html文件里埋下至少1个验证码,同时又用css代码将这个网页上的验证码隐藏起来,因此真人是看不到的,但是网络机器人没有眼睛,它们只会分析网页代码,看到有验证码就会主动填上,且无法分辨出这些html文件里的验证码是否早已被存储在其他文件夹里的css代码隐藏起来了。一旦填出来,它们“伪人”的身份便暴露了。
这是一个很有趣的反向操作。尤其将“常规的验证码系统”和“HoneyPot”搭配使用时——作为没有眼睛只会分析代码的网络机器人,若填不出前者,就必定暴露“伪人”的身份;若能填出前者,就必定也能填出后者;若能填出后者,最终还是会暴露。当然,随着AI的发展,HoneyPot或许也不再会屡试不爽,但是它依然能拉高AI的破解成本,从而将那些AI驱逐到其他破解起来相对更经济、低防御的网站。扯远了,其实我真正想说的是——即便你不懂代码,但是如果你能读懂这些功能架构的设计逻辑,或许也会为这些“漂亮”的想法而拍手称快吧?
时至今日,我早已放弃了drupal,但这并不妨碍我心存其它幻想,我依然觉得我可以用wiki.js去构建一个有关古希腊罗马钱币的在线百科;或者给我的blog重新写一个更极简的主题。当然,时下的我,可能更乐于去用AI整理过去二三十年间,在那些老派的欧美古钱币论坛里流传着的各种名人轶事、八卦奇谭。我想,这可能也是我想坚守blog这种古早书写方式的一个原因,回想我20多年的欧洲古钱收藏历程,在coinsky的外币板块泡论坛无疑是一段快乐的时光,论坛的好处在于它比微信社群更具有专题化、去碎片化;比小红书、抖音更封闭些,参与的目标受众更垂直、专业些;最关键的是它可以保存很长时间,相对易于检索,与移动设备的存储是弱依附关系。所以blog大概也是这样一种很好的记录工具,笨拙却可靠。
所以为什么要自己做一个blog?因为可以在一个公开却又人迹罕至的自留地里发癫自high;因为可以自定义各种、掌控一切;因为可以文理兼修、其乐无穷~